Sometimes, not often, I accidentally achieve results that look too marvelous to be real. But they are. Just like in this case.
Last week I assigned Petr, our internal system developer, the task to optimize one server-side script. The script recently started taking over 8 hours to run and reaching the expiration limit we have set for it. When I tried his optimized script on live data I was honestly surprised. It took less than 2 minutes to run (over network).
My first thought was there must be something wrong. But the script was returning correct results. After further examination I could confirm that it really does what it is supposed to do.
Let me show you what and how Petr actually optimized...
A Little Background
This looked like an easy request a few months ago. We were supposed to implement report of stock inventory at a specified time. We had hundreds of items on stock and thousands of items historically in our system. We have a pretty generic inventory data model: we have a table of goods and a table of transactions.
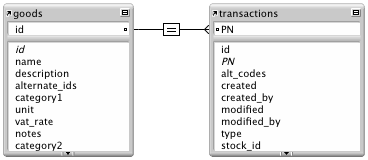
To speed the report up we used auto-enters to keep the updated quantity on stock in each transaction record. But to be able to pull this information for any timestamp in history, we had to create a LAST flag defined as an unstored calc using relationship to previous transaction and comparing transaction timestamp to the report timestamp, whose result was 1 if it was the last transaction for the specific item with older or equal timestamp to the report timestamp.
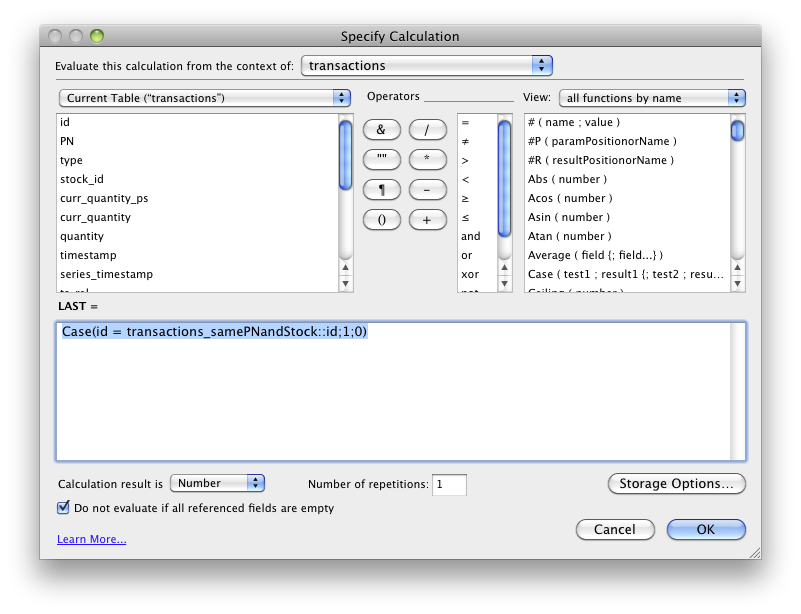
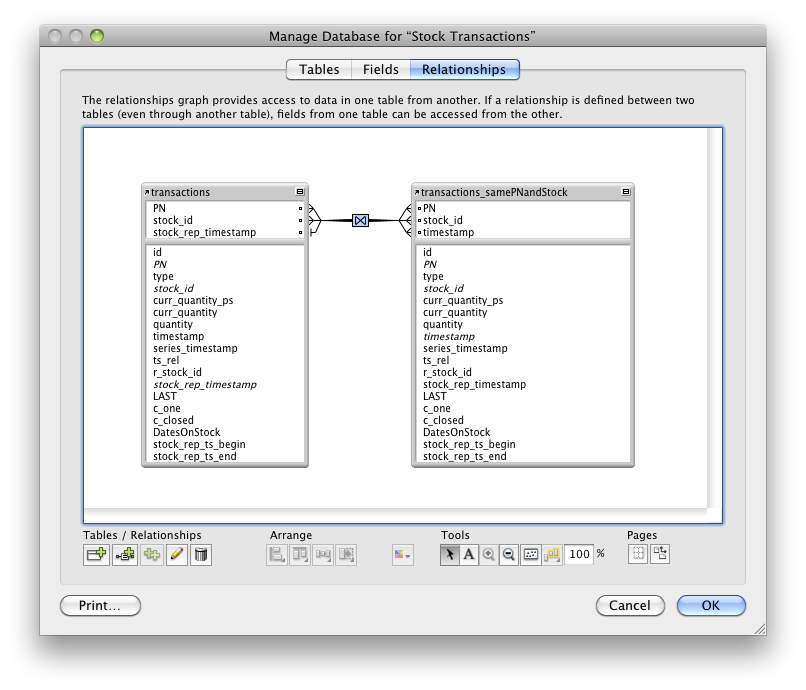
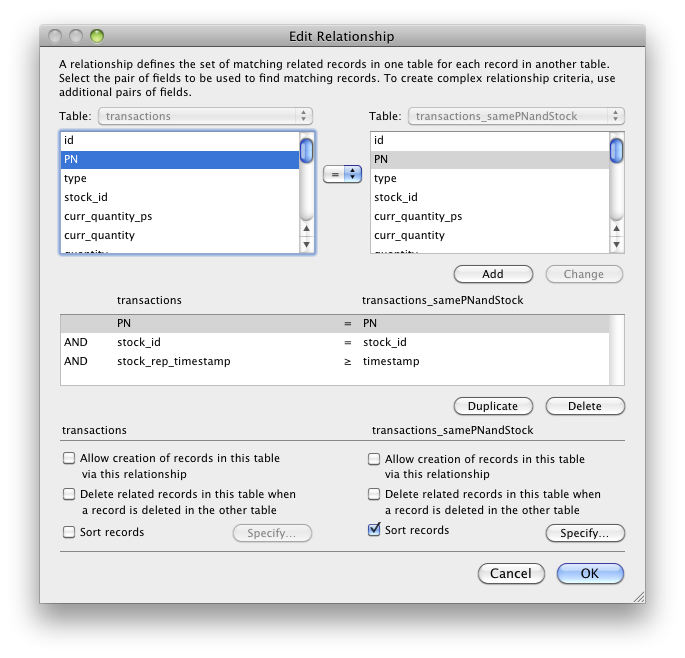
Geneating the stock report this way originally took around 40 minutes, 35 minutes of which was performing find in the unstored calc field.
First Optimization
We never know in advance what time we will be generating the report for. So we thought there was no way to pre-calculated the results over night. But after brainstorming this issue in our team we came up with a solution. We created a new field DatesOnStock in the transactions table. It's a regular text field because date field cannot hold more than one date. Every first day in a month, we ran a script over night which found the last transaction for every item with positive quantity currently on stock. Then in every found record it added the current date to the DatesOnStock field.
For example, if a specific item was received on January 5, 2010 and then there was no transaction until June 20, 2010, the DatesOnStock field in the receiving transaction from January 5 will finally end up containing all these dates:
2/1/2010
3/1/2010
4/1/2010
5/1/2010
6/1/2010
Now when we wanted to report items on stock on March 3, 2010 at 12:00 we performed this optimized find:
- Find all transactions with the date 3/1/2010 and all transactions whose timestamp is between 3/1/2010 0:00 and 3/3/2010 12:00
- Constrain found set to transactions with 1 in the LAST flag
The report which had been originally taking around 40 minutes and getting slower as we were adding data now took around 40 seconds and its speed did not depend on the number of obsolete transactions stored in the system. 60 times faster reports and most of the workload done only once a month over night. Not bad, right?
Then we did a physical inventory counting and generated a lot of transactions in a single day, and a new episode of the story began...
The Killer Optimization
The physical inventory revealed something that was already happening but we had not noticed yet. Both the over-night script and the report script were quickly slowing down as we were adding goods and transactions. On March 1 the server-side script did not finish because it exceeded the time limit we had set for it (you can set a time limit for a server-side script and FileMaker Server will halt the script when it exceeds the limit).
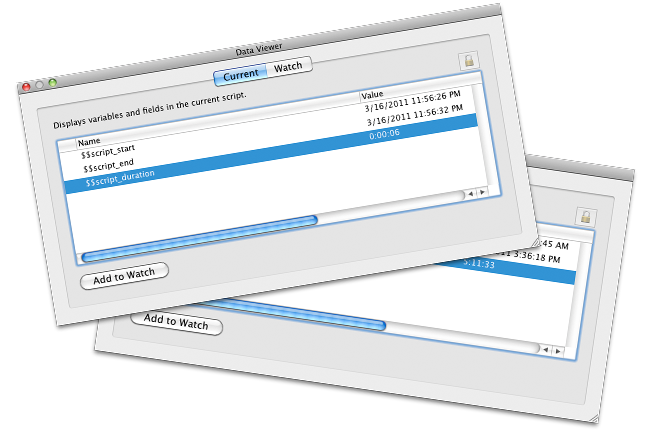
To verify why the script did not complete server-side I pulled it off the server and tried to run it locally. To measure the execution time I stored the start and end timestamps of the script in global variables.
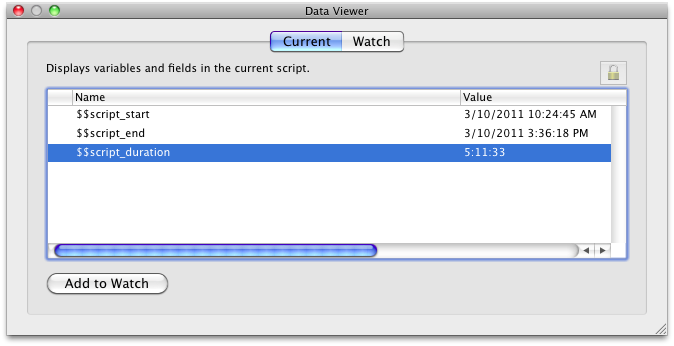
This confirmed my fear: 5 hours were really bad for a locally executed script. So we had to optimize the script further but didn't have a clue how. Until we dicovered another issue...
Having around 50 thousand records in the transactions table, the find performed on the LAST flag turned out to be not only slow but also unreliable (at least when done over network). We discovered that it did not find all the records having 1in the LAST field. Even weirder, the resulting found set also contained a few items with 0 in the field! And what was worst, it did not return the same found set when we performed the find multiple times. We are now trying to describe the issue and prepare a test solution demonstrating this so that we can report it as a bug to FileMaker.
In the meantime, of course, we had to make our system work. So I told Petr: "Rewrite the scripts to not use the unstored calc even if you will have to walk through all the 50 thousand records in a loop and let's hope the solution you find won't be slower than the current broken one."
The result was unbelievable.
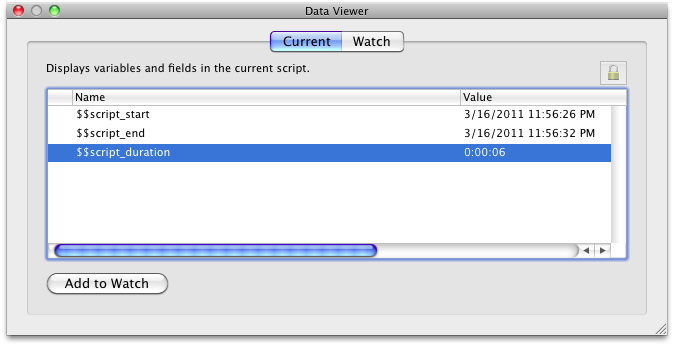
Petr cut the execution time of the script from 5 hours 11 minutes and 33 seconds to just 6 seconds.
That's a 311 thousand percent speed increase!
And guess what, the new script really does go through all the 58,525 transaction records in a loop.
See what the two scripts look like:
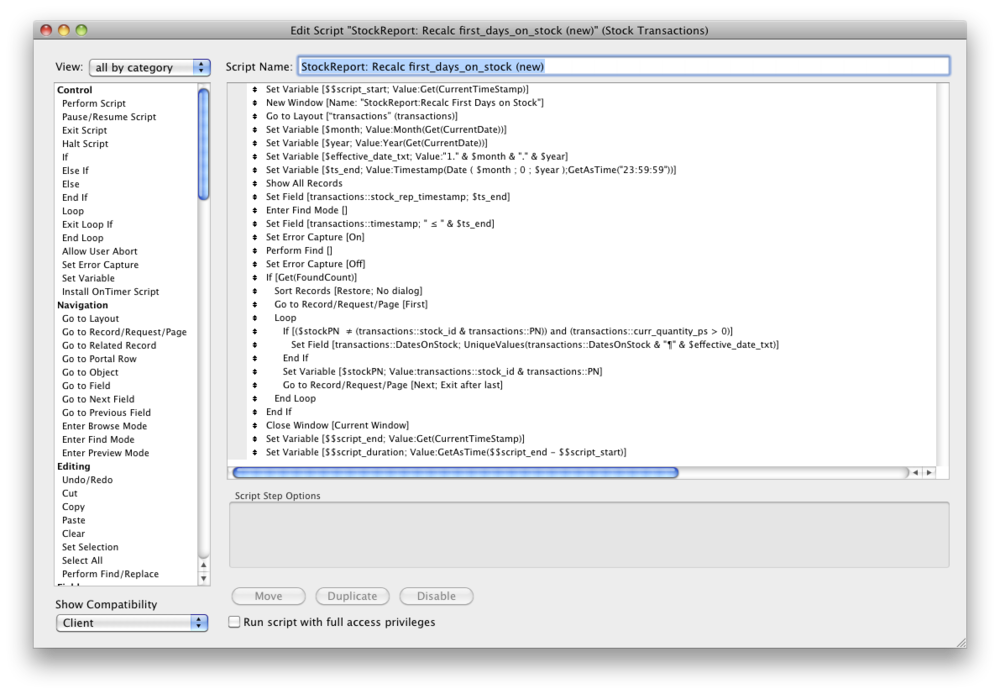
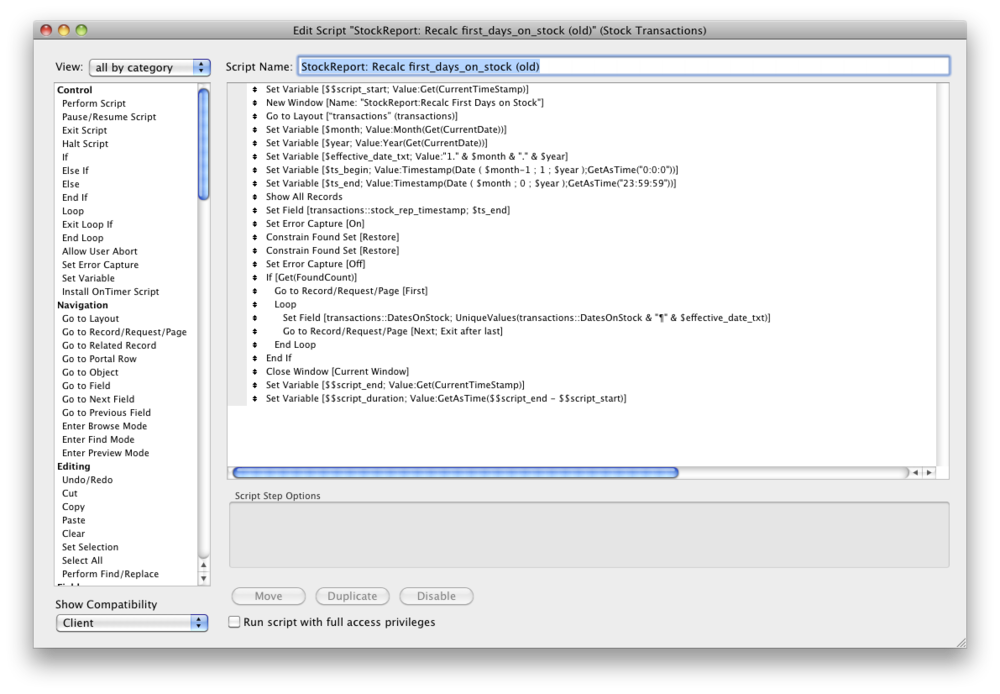
Doesn't it look like a miracle?
The Marvelous Optimization Formula
OK, let's add a bit of self-reflection. I have discovered something I call "Marvelous Optimization Formula". It works like this:
- The more marvelous it appears the less you believe it is the right way.
- The less you believe it is the right way the more probably you're going to do it the stupid way.
- The more stupid way you do it the more marvelous the right way appears.
Got it? The main reason this optimization looks so marvelous is that the original approach was so much more stupid. Just think about these questions for a moment:
- Considering how we defined the LAST flag calculation, what does it take to evaluate it for a single transaction?
- Now what does it take to evaluate it for two transactions with the same PN and Stock ID?
- How about 3 transactions of the same PN and Stock ID?
Now consider this: we have 58,525 transactions and only 4,709 PNs. That's 12 transactions per PN in average, but the reality is that most of the PN's have zero or one transaction, so it's many more. You have probably already concluded that the execution time grows exponentially with the number of transactiosn per PN...
The reason we used this stupid approach was even more stupid. I tend to think that scripts are in general slower than calculations. So when I first discovered I need to find every transaction which is "last in specified time period for the specified PN and Stock ID" my next thought was: "how do I find out if this specific transaction is the last one for this PN and Stock ID in the specified period?" And I turned this question to a calculation.
Then we created the report script using this calc and it took about 40 minutes to run. Long enough to make the right way look too marvelous to even think about it...
The lesson I have learned
The Marvelous Optimization Formula works. People will always keep doing things the stupid way. Therefore there will always be a chance for a marvelous optimization when something starts becoming useless. And the fix often is as easy as replacing the stupid solution with the normal one. Not necessarily genius, just normal.
You know, we still have to optimize our solution a little bit, for example by taking the previous values in the DatesOnStock field into account and not walking through all transactions every month if it is enough to walk through the new ones only.
And by the way, I have to remember that scripts don't necessarily have to be slow when it is possible to loop through 50 thousand records in 6 seconds... So if you have a FileMaker solution that's extremely slow, try to ask yourself: am I not just doing something the stupid way?
How about you?